Batch Normalization:
论文链接: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。
1. Batch Normalization:
简单描述:Batch Norm的主要目的就是独立地归一化Feature Map,使其符合零均值和单位方差,下图是原论文中的描述:

首先来讨论下使用Batch Norm的原因。众所周知,如果输入经过白化处理后,网络的收敛速度将会加快,但是这个过程消耗很大,并且在每次更新参数时,需要重新分析整个训练集。
然后来一个使用顺序:Conv=>BN=>Acn,假如有一个输入$X$(维度为$[C,H,W]$),在经过卷积操作后的输出$Y=w·X+b$,这个$Y$再经过激活函数处理后可以被视为下一层的输入。
而会随着网络层数的加深或者在训练过程中,其分布会逐渐发生偏移(论文里称为:Internal Covariate Shift),也就是$Y$的值将会逐渐靠近非线性激活函数作用域的上下限(例如:Sigmoid函数横轴上,很大正值或负值的位置),而这些位置非线性激活函数的导数接近于0,因此就有梯度消失的情况发生,从而导致神经网络的收敛变慢。
而如果我们把Batch Normalization放到卷积层和激活函数之间,将跑偏的分布拉来回来,也就是说使得非线性激活函数的输入值位于其有效作用域之间,因此在即便是经过归一化后,输入发生变化的效果会急剧缩小,但是即便是很小的一点变化出现时,也可以使得损失函数有较大的变化,从而增大梯度,避免梯度消失的问题,并且加快网络模型学习收敛速度,从而加快训练。
下图是原论文中给出的公式:

下面,根据上图给出的计算公式接着说,首先前三个公式,计算一个batch中所有样本的方差$\sigma_B^2$和均值$\mu_B $,然后用每一个样本减去其均值$\mu_B $,最终除以平方差$\sqrt{\sigma_B^2+\epsilon}$,($\epsilon$是一个非常小的值,主要就是为了防止出现方差$\sigma_B^2$为0的情况),然后就得到了符合方差为1、均值为0的分布。
这里借用一下,一位大佬博客里的图(之后补上引用链接),这个例子计算的很清晰。
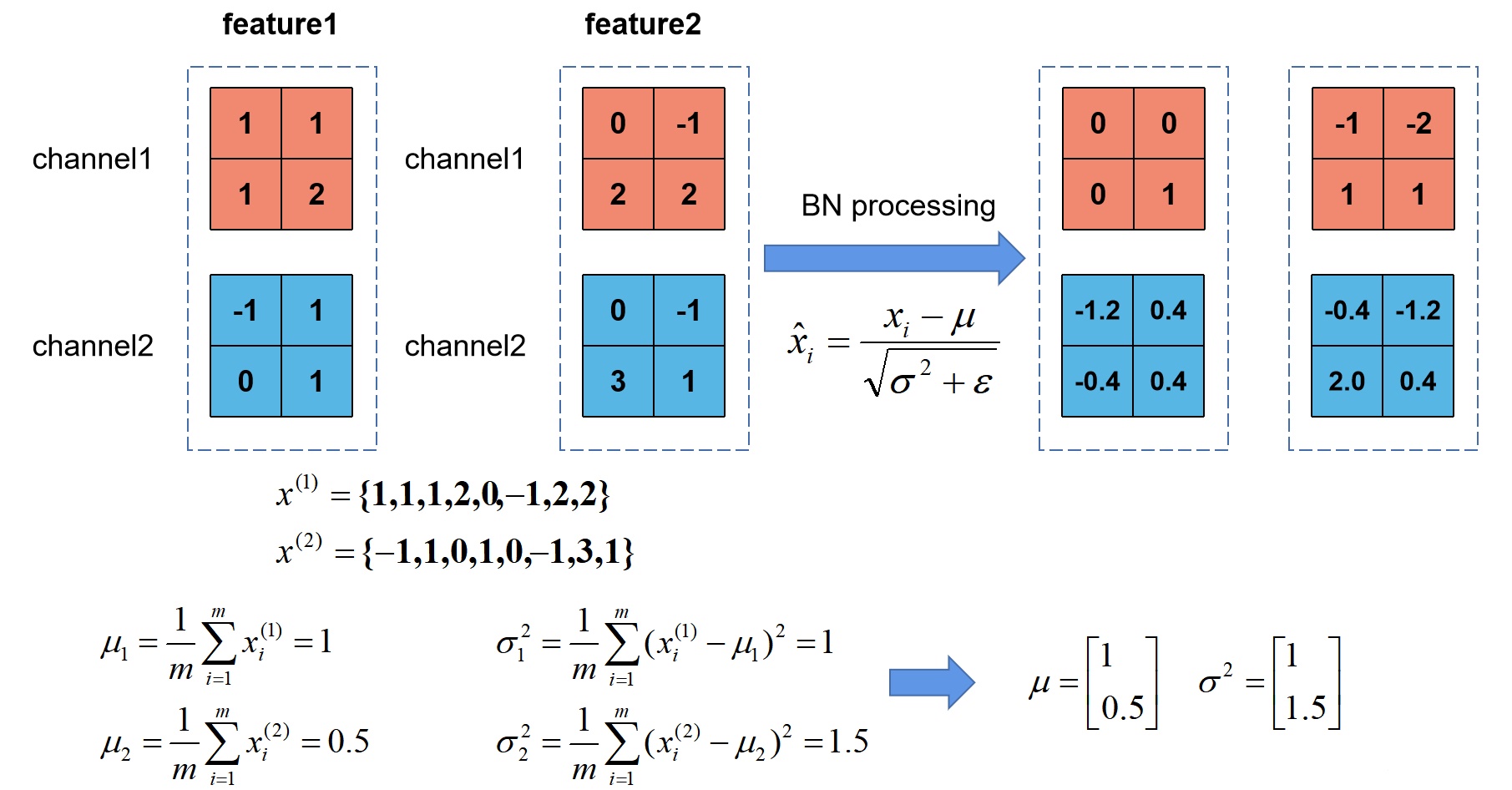
但是通过上面的描述,会发现这样都通过Batch Norm之后,那非线性激活函数不就几乎等同于线性函数了么,网络的深度也就失去了意义,因此Batch Norm为了保证非线性的效果,就对变换后的$Y’$,进行了scale and shift操作,通过$\gamma$和$\beta$来调整,它俩的初始化可以分别是1和0,然后再通过反向传播进行调整,也就是等价于非线性函数的值,从中心往周围挪了一下。因此Batch Norm最终可以享受到非线性的好处,又可以避免因太跑偏而导致的收敛速度慢。
训练过程中一个mini batch的$X$(维度为$[B,C,H,W]$),Batch Norm作用的范围就是$[B,H,W]$,而在测试的时候方差$\sigma^2$和均值$\mu $则是将训练过程中的所有batch的均值和方差保存起来,求均值的期望和方差的无偏估计(公式表达如下),也就是说test时,Batch Norm参数要固定,而eval模式要打开。
\[E[x]=E_B[\mu_B]\] \[Var[x]=\frac{m}{m-1}E_B[\sigma^2_B]\]最后说下,为啥现在的卷积网络Dropout的使用逐渐在变少,首先Batch Norm和Dropout一样拥有正则化功能,而Dropout在卷积上的正则效果是有限的,此外卷积相对全连接层而言参数量更少,而且激活函数也可以完成特征的空间变换,而Dropout表现很好的全连接层,它的作用正在被全局平均池化代替,因为后者不但可以减少模型大小还可以提高模型的表现。
上面说了Batch Norm测试和训练时候的区别,这里也简单补充下Dropout的吧,Dropout在训练时就是按照失活概率$p(0-1)$,对这一层的神经元按照p的概率进行失活,也就是失活神经元的输出为0,恢复失活神经元(失活神经元保持原状,未失活神经元更新),然后对第二层输出数据除以1-p之后再传给下一层,作为神经元失活的补偿。而在测试的时候是不会有Dropout的,因为如果不除的话,就会导致下一层的输入和期望会有差异。
2. 对比:
下图为常见Norm操作的作用情况,这里就简单做个比较,之后用空再详细展开。
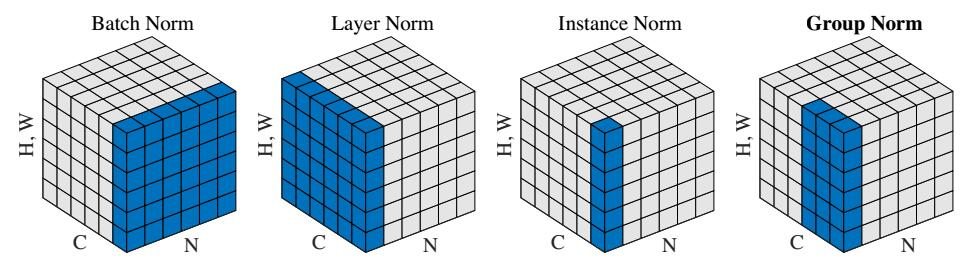
| 名字 | 作用位置 | 作用维度表示 |
|---|---|---|
| BN | batch | B,H,W |
| LN | channel | C,H,W |
| IN | channel内 | H,W |
| GN | channel分为group,group | C//G,H,W |
这里就简单插一句,Layer Norm在之后所写的Transformer中有所提到,Batch Norm在batch size较小的时候,这个batch的数据的方差和均值代表性就比较差,而在目标检测、分割等输入图像较大、维度较多,batch size一般都比较小,因此Group Norm的效果会更好一些。
文档信息
- 本文作者:Guoziyu
- 本文链接:https://mateguo1.github.io/2020/08/29/Batch_Normalization/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)