ResNet
论文链接:Deep Residual Learning for Image Recognition
1. 两个问题:
ResNet主要是为了解决,神经网络在训练过程中出现退化的问题,以及在层数太深时,数值稳定性会发生的梯度爆炸、消失的问题,首先来介绍下这两个问题:
1.1 退化(degradation):
退化问题,可以简单理解为,随着网络层数不断加深,准确率出现饱和,然后迅速下跌,而它不是因为过拟合而导致的。下图是原论文中给出的说明图,论文提出使用深度残差学习框架来解决这个问题。

1.2 梯度消失、爆炸(Vanishing/exploding gradients):
这里暂时参考之前的博文 Batch Normalization 中的内容,之后再详细补充。
2. 残差结构(Residual Block):
2.1 基础块:
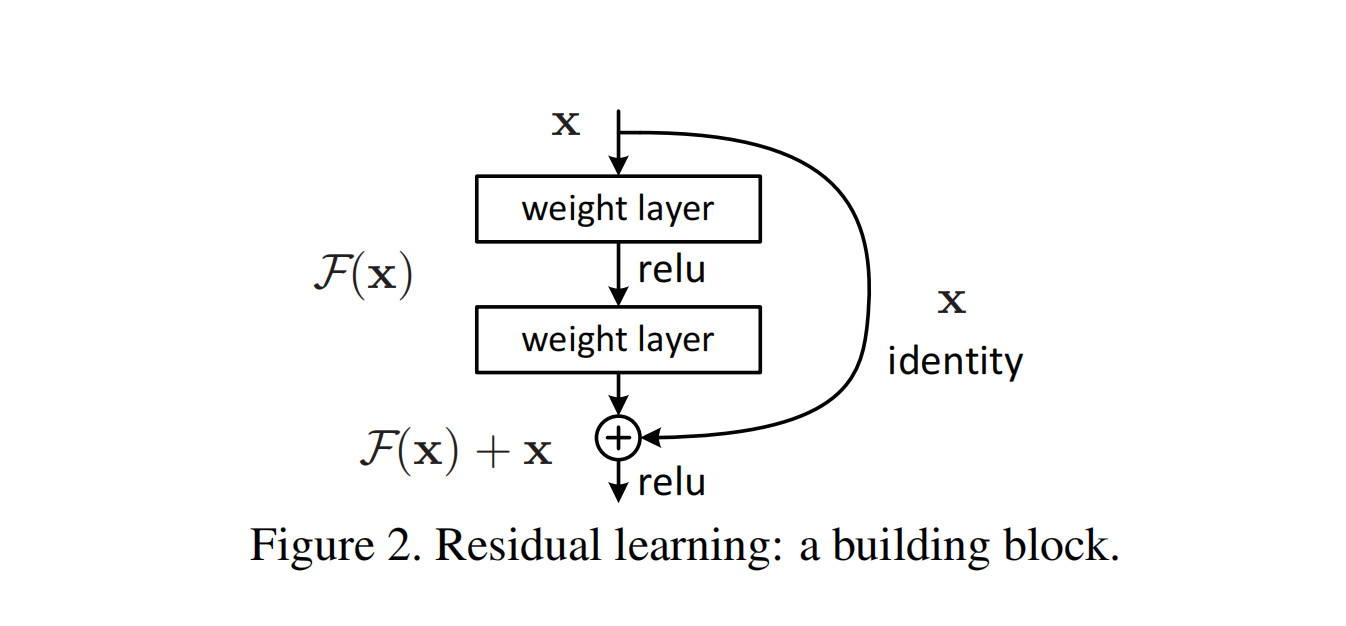
上图是原论文中给出的残差结构块,其中的weight layer,可以理解成$y=w\cdot x+b$中的w,或者更直接地替换为卷积层,而右侧的曲线identity也就是论文中所提到的捷径连接(shortcut connection),暂且理解成一个恒等映射(identity mapping),这里暂且的原因下文中会说明,不用过于纠结。
上图结构最终通过公式的方式,总结公式为:
\[y = F(x,{W_i})+x \qquad\qquad(1)\]2.2 整体结构:
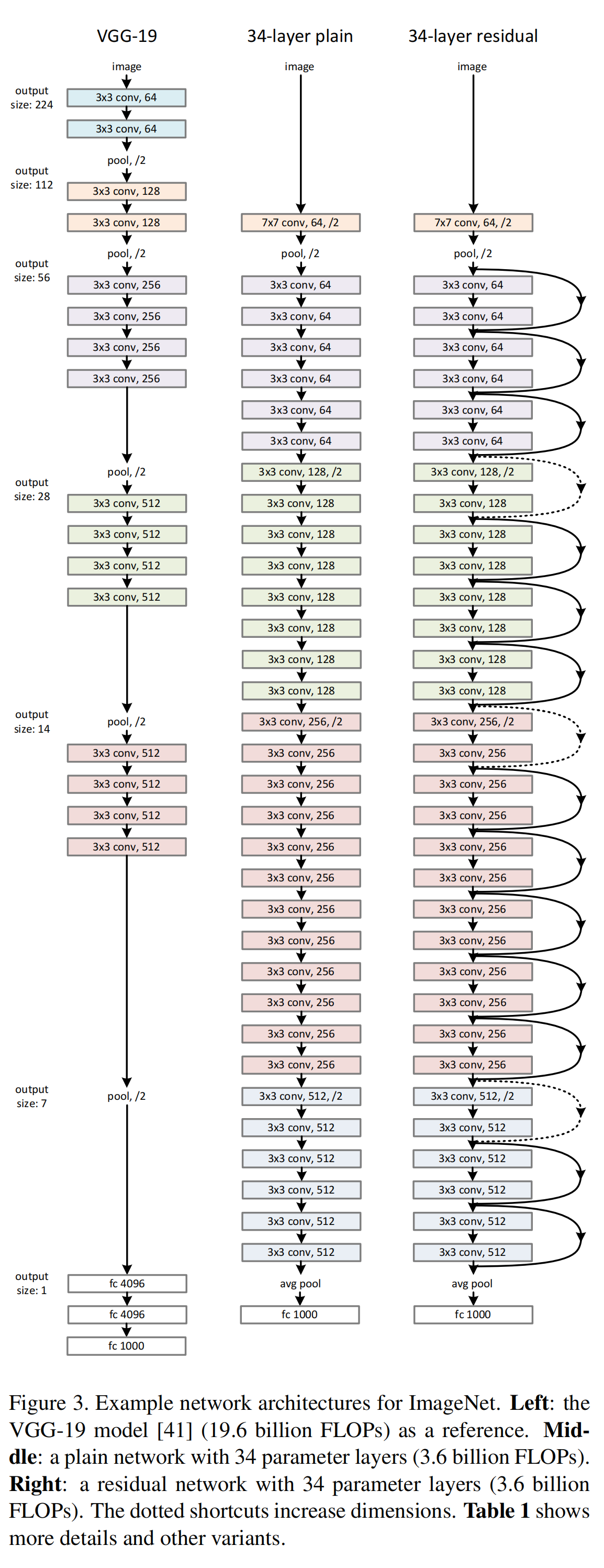
上图是原论文中给出的ResNet-34与VGG-19和对应的朴素网络(Plain Network)的结构对比示意图,这里作者为了保证实验一致性,遵循了两个规则:1)为输出相同大小的feature map,这些层应有等量的filter;2)若feature map大小减半,那么filter的数量应该加倍,从而保证每层的时间复杂度相同。
此外从上图可以看到捷径是有实线(solid)、点线(dotted)之分的,其中实线也就是如公式 (1) 所表示的含义,点线(具体在方法2中有讲述)原论文中则给出了两种解决方法:
1)捷径仍然执行恒等映射,并加入一些额外的零实体来保证最终形状相同,这样的好处是不会添加额外的参数;
2)则是使用线性映射(linear projection)来替换恒等映射,像是 $1\times1$ 的卷积操作来改变形状。这里根据公式 (1) 详细展开下,其中的相加操作是从像素级、通道对通道来进行的。此外,经过一系列的$F(x)$产生的 $y$ 需要保持和输入 $x$ 相同的形状。而如果产生的 $y$ 与 $x$ 的形状不同的情况,则需要使用点线的方法来操作,同时公式变为:
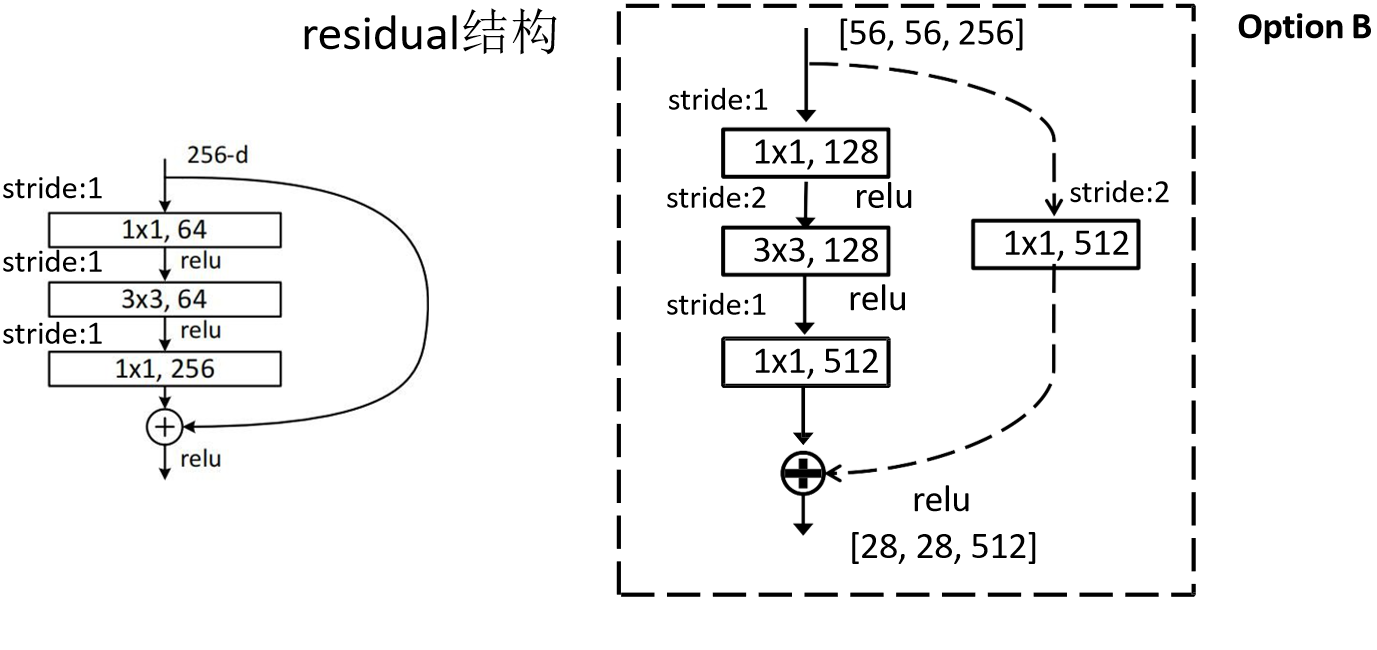
\(y = F(x,{W_i})+W_sx \qquad\qquad(2)\) 根据下图中的两个残差块结构,扩展一点内容,左边结构主要是使用在ResNet-18 和 ResNet-34,右边的结构主要是使用在更深层的ResNet-101和ResNet-152,也被称为bottleneck结构。
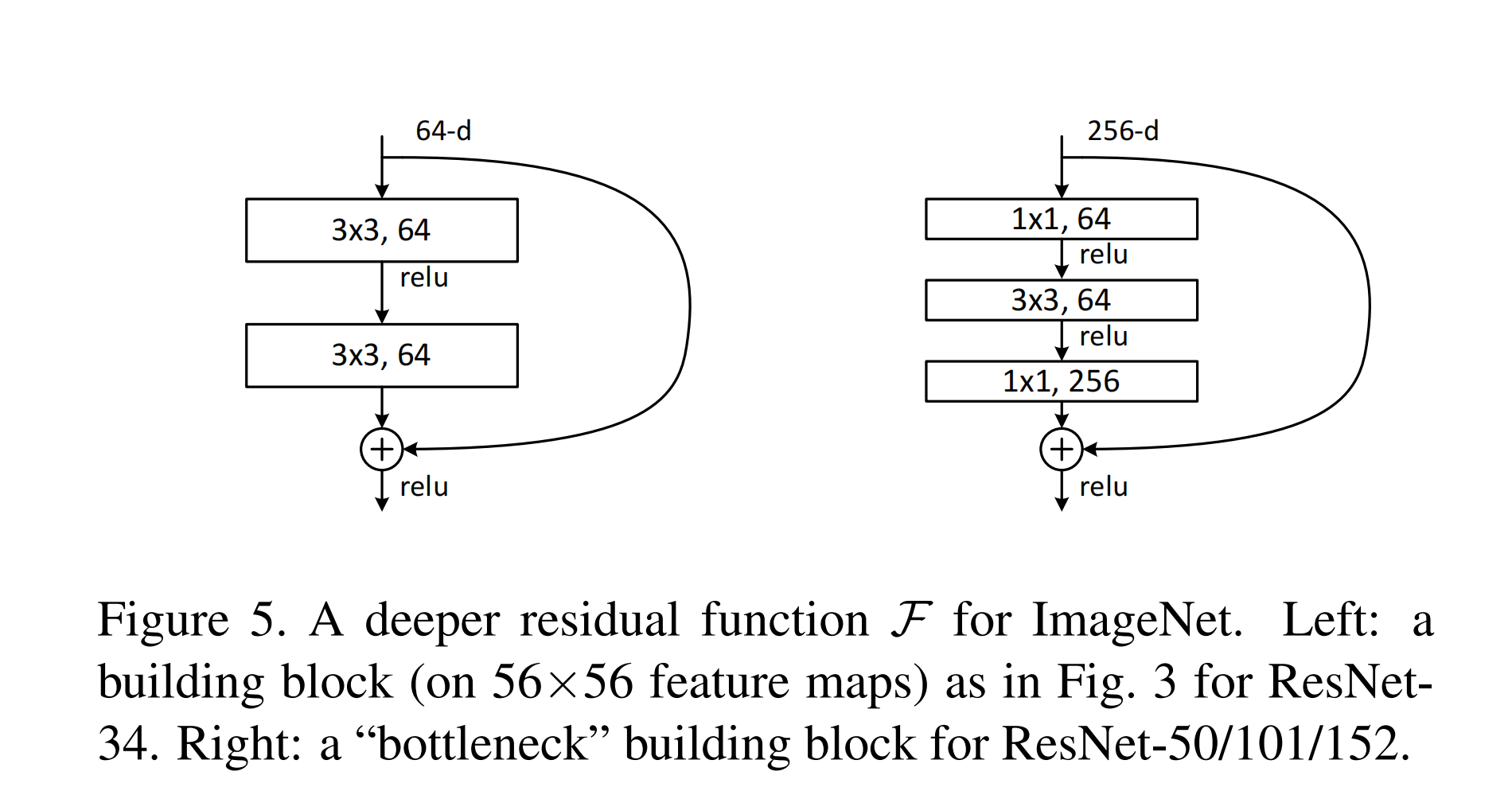
浅层卷积结构上面已经介绍过了,而至于为啥深层的ResNet使用右边的这个残差块,我觉得是参数计算量要小很多,可以通过输入尺寸为(3,256,256)来计算一下,这里注意要保证上述提到过的条件外,同时还得保证最终两块feature map尺寸相同,所以就得把左侧层数调整为256,计算结果为如下,很明显,右侧运算次数要远少于左侧的。
左:3×3×256×256+3×3×256×256=1,179,648
右:1×1×256×64+3×3×64×64+1×1×64×256=69,632
下面分析下整体的网络结构:
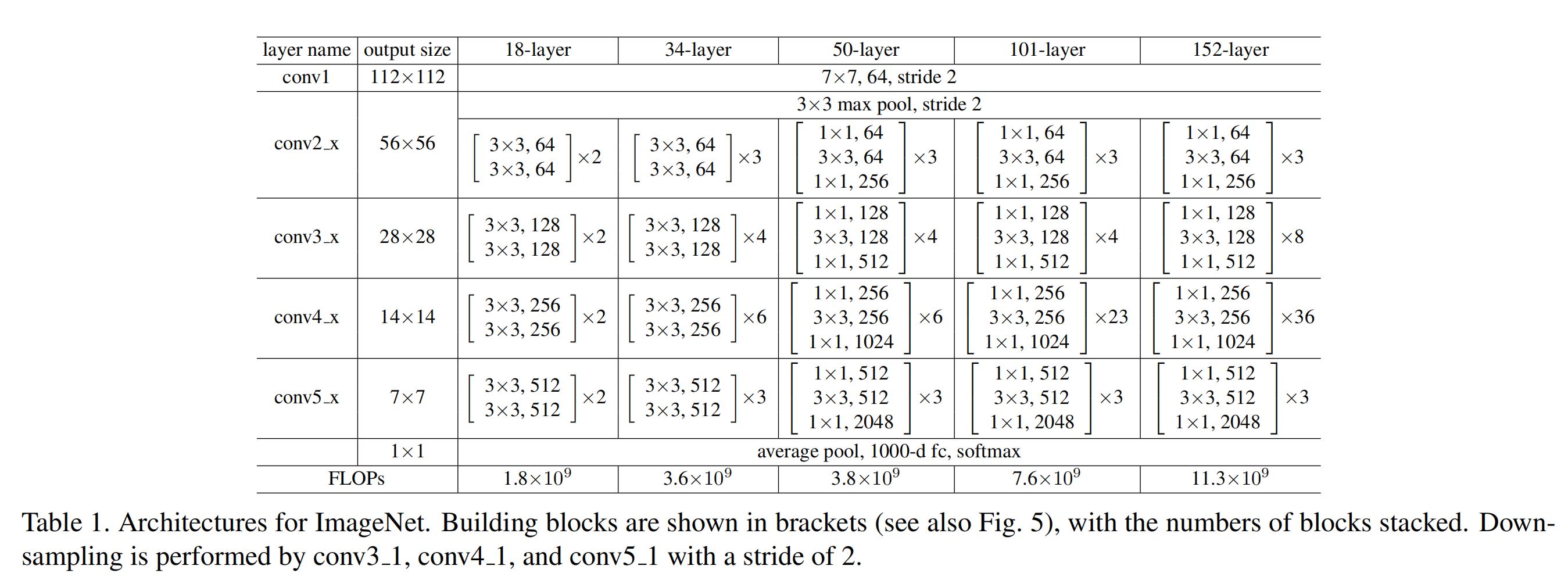
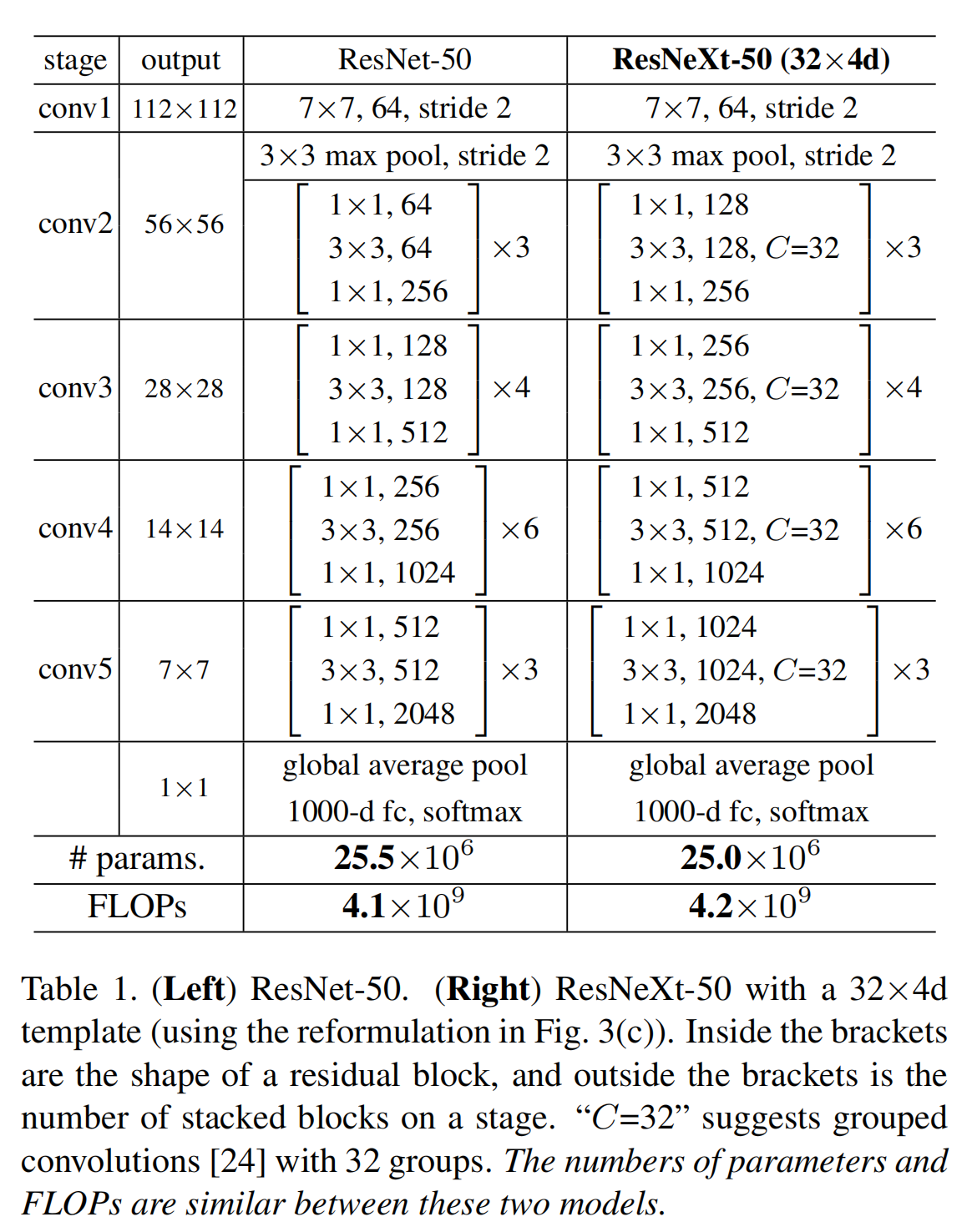
下表是原论文中给出常用ResNet网络结构参数,可以看到output size那里,每一层feature map的size都缩小为之前的1/2,而我们通过计算可以知道,conv2_x那里的缩小是因为max pooling操作导致的。
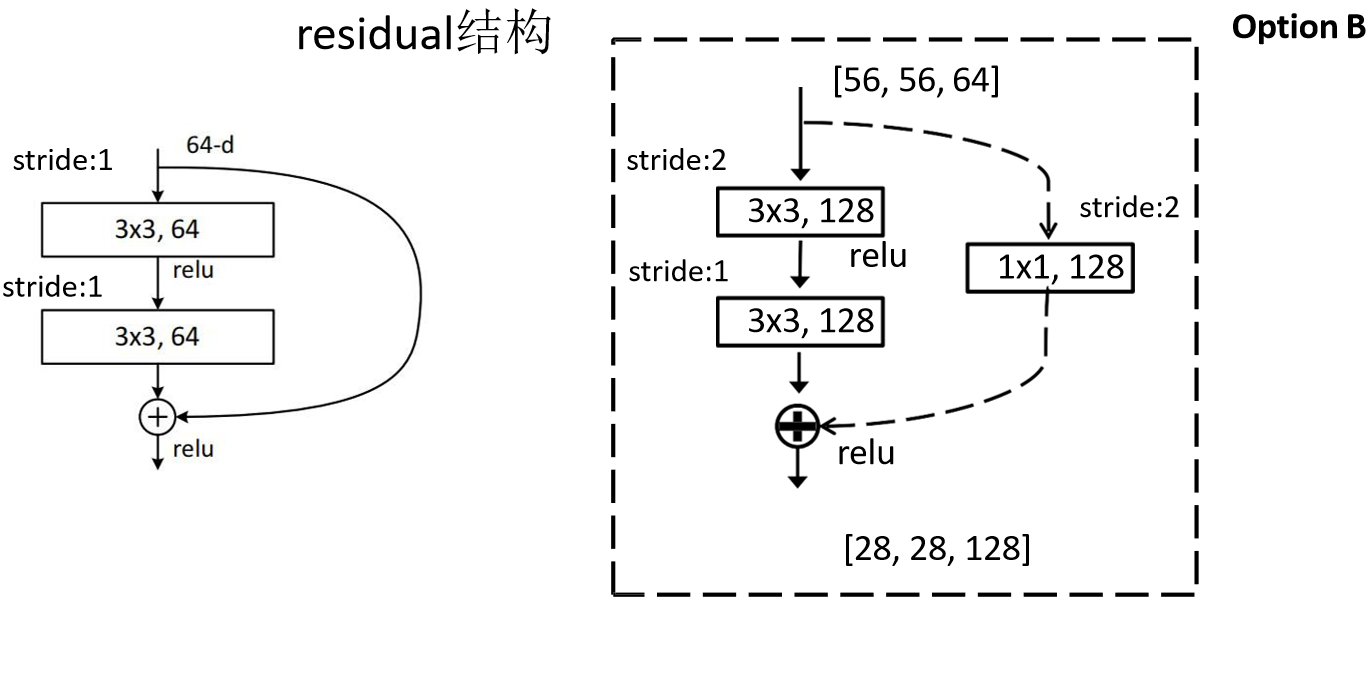
而下面的conv3_x、conv4_x、conv5_x,则是通过blocks中的第一个block来减小了feature map的size,同时扩大的channel数。也就是说,conv3_x、conv4_x、conv5_x中的blocks的第一层都是上两图中右半部分的结构。
至于为啥stride=2,就缩小为1/2,根据$out = ( in+2*padding-kernel_size )/stride+1$计算,就可以得到。当然了这里仍然要保证输入输出的尺寸相同,因此虚线部分也要扩大channel。
最后贴出代码,方便扩展理解:ResNet Colab。此外,论文中还使用了BN和学习率衰减等策略,这里不再详细展开,可参考我的其他的博文。
3. ResNet V2:
论文链接:Identity Mappings in Deep Residual Networks
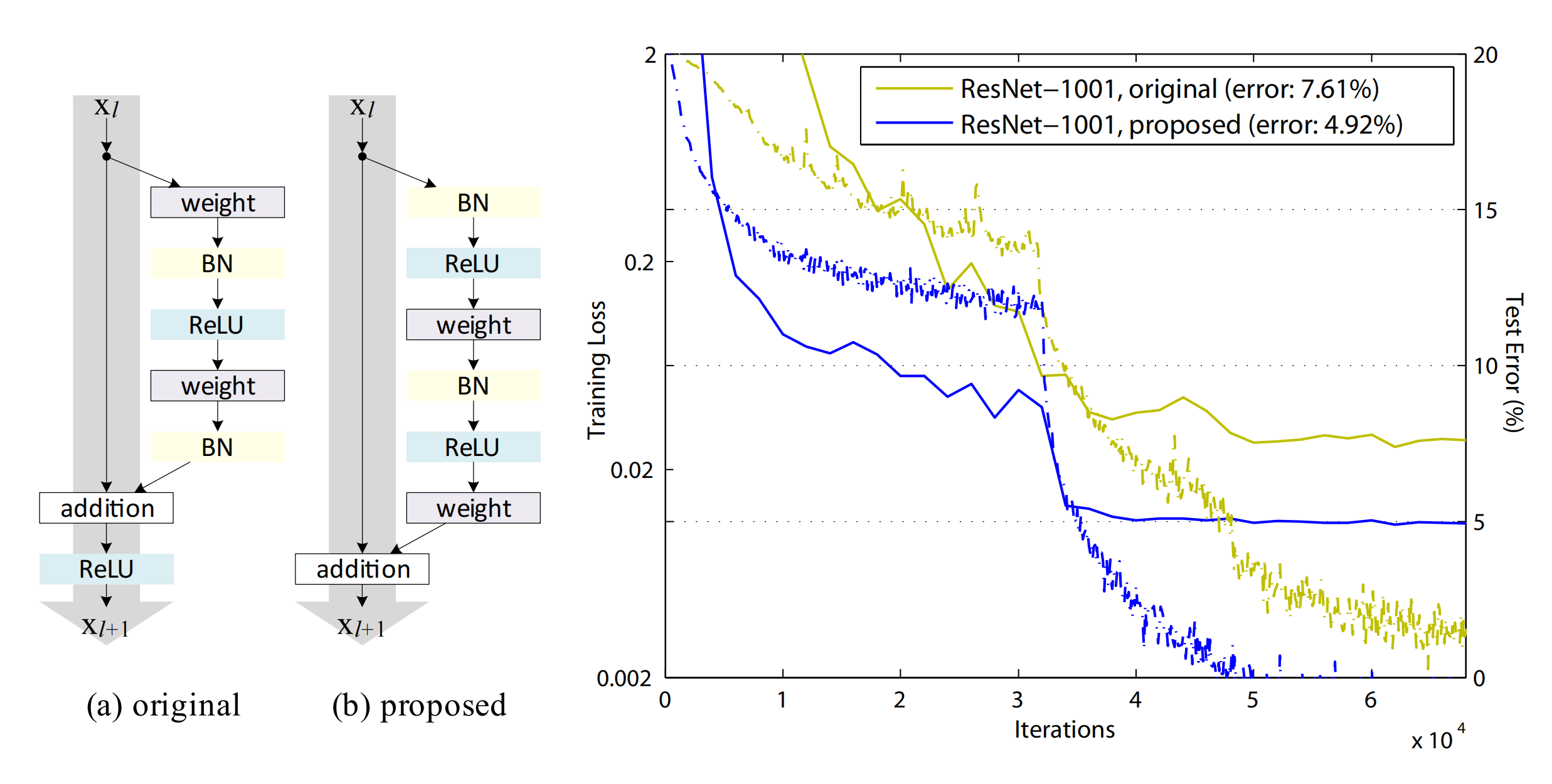
做了好多对比实验,最终得出了哪个模块摆放顺序的效果最好的结论,具体内容,我理解的也不是很透彻,这里先单独放一张原文的结构对比图,暂时先不详细展开了。
4. ResNeXt:
论文链接:Aggregated Residual Transformations for Deep Neural Networks
结合了Inception-ResNet和Grouped Convolution的特点提出的网络结构,在保证和其他论文同水平的准确率、浮点运算复杂度和参数量前提下,能够实现更好的扩展性和适用性。
首先来看一下,ResNet的残差模块和ResNeXt中模块结构对比,其中有一个参数命名为cardinality,简单理解就是横向重复单个模块32次。
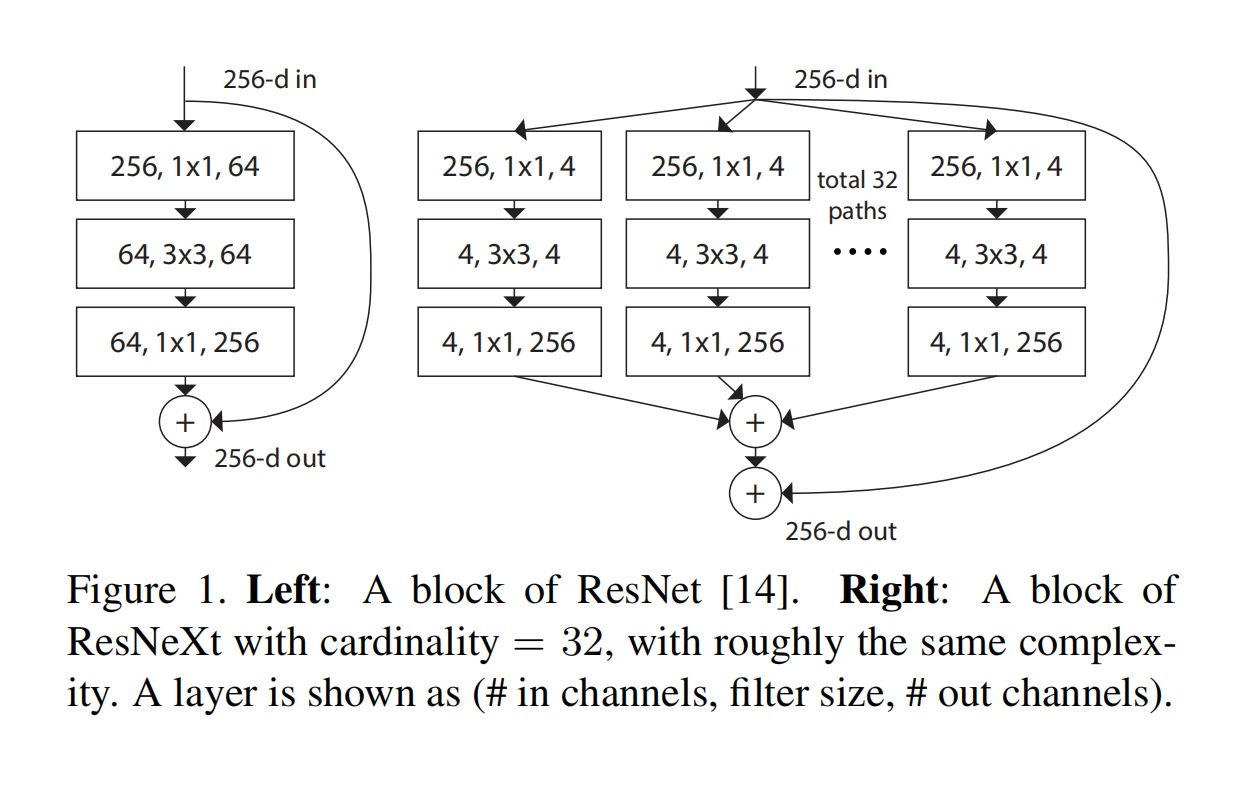
论文中提到一个名为split-transform-merge的策略,就是Inception中模块将输入先通过$1\times1$卷积进行降维分割,再分别通过$3\times3$和$5\times5$的特定卷积,最终在叠合在一起。
下面是原论文给出的ResNeXt50和ResNet50具体参数的比对表:
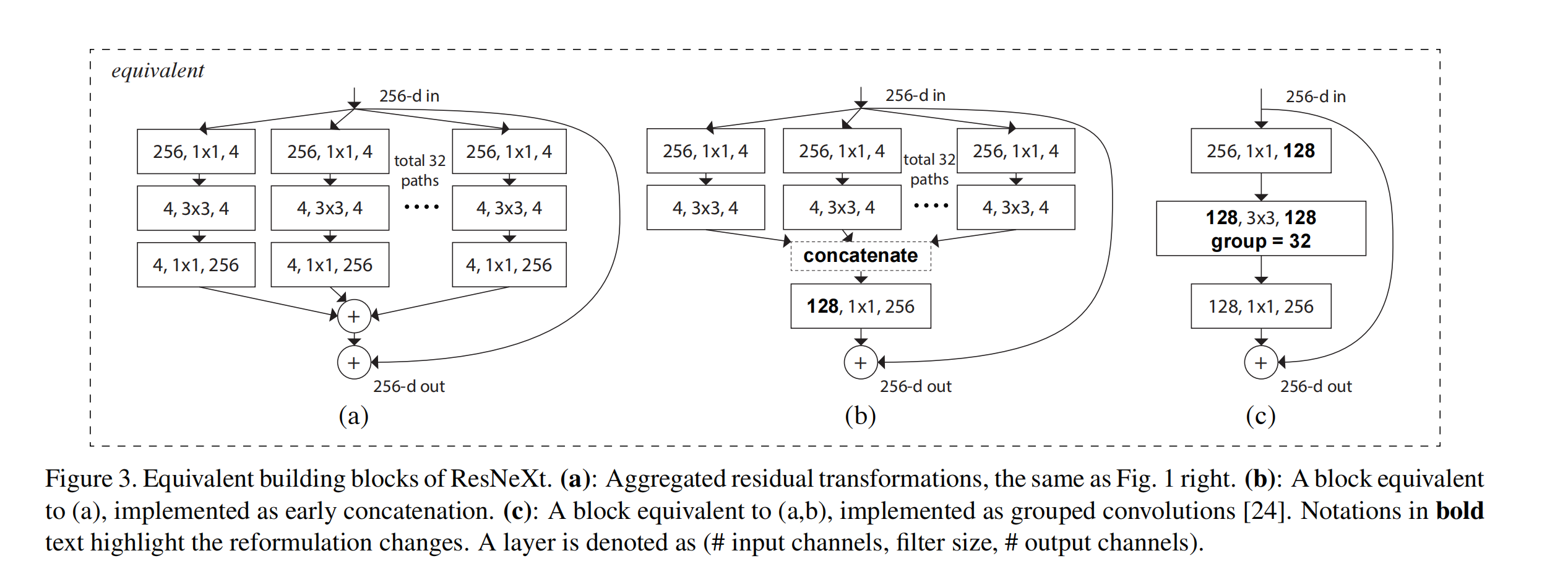
下图是论文中给出的三种结构,文中提到这三种结构是等价的,而作者最终选择了更加简洁和快速的 $c$ 结构。顺便提一嘴,原文讲模型的第三部分写的很详细,非常值得一看。
文档信息
- 本文作者:Guoziyu
- 本文链接:https://mateguo1.github.io/2020/09/01/ResNet/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)