MobileNet:
MobileNet是2017年由Google团队提出的一种专注于嵌入式、移动端设备的轻量级卷积神经网络。相比传统卷积神经网络,在牺牲一小部分精度的前提下,极大程度地减少模型运算的参数量,论文链接:MobileNet V1、MobileNet V2、MobileNet V3。
下面就按照顺序来简单介绍下MobileNet系列网络。
1. MobileNet V1:
分解卷积:
深度可分卷积,Depthwise separable convolution
主要思想:将卷积的滤波和结合功能,分别通过深度卷积和点卷积来实现,从而减少模型计算量和参数大小
宽度乘数,width multiplier,$\alpha$,(0,1],控制feature map的channel数
分辨率乘数,resolution multiplier,$\rho$,(0,1],控制input的尺寸(长宽)
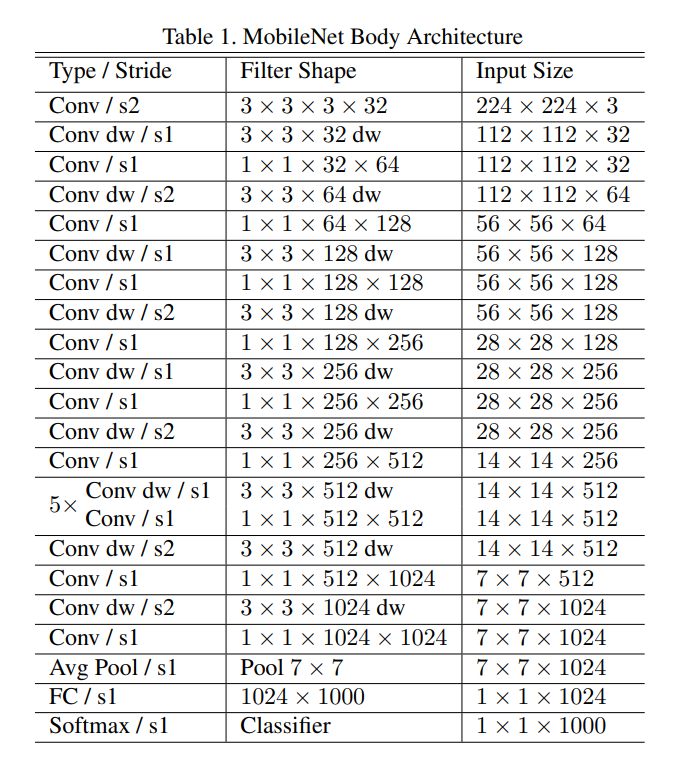
下图是原论文中给出的网络结构,V1 主要是使用了深度可分卷积DW和超参数α、β。
1.1 深度可分卷积:
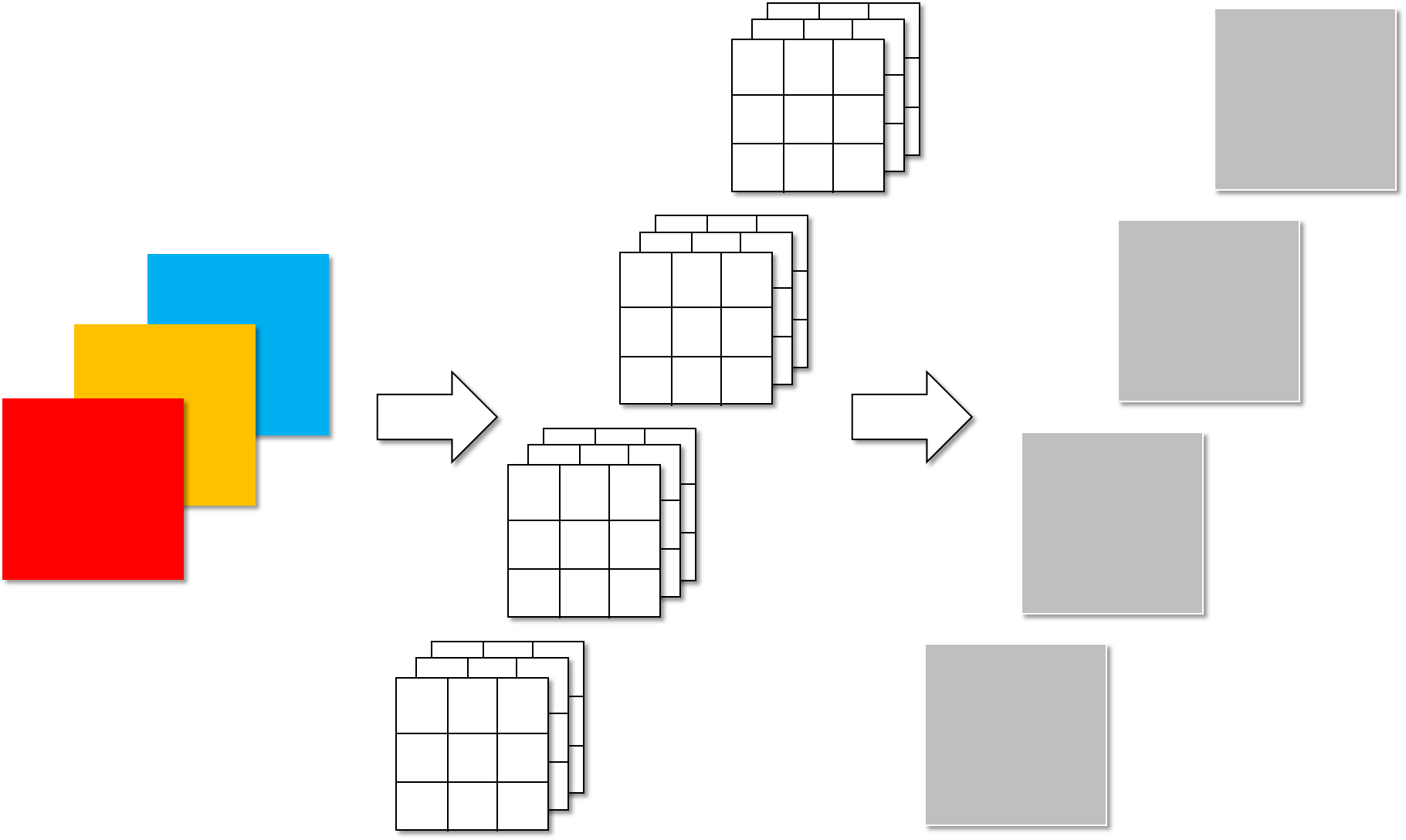
MobileNet V1使用深度可分卷积(Depthwise Separable Convolution),使用分解卷积的思想,将卷积的滤波和结合功能,分别通过深度卷积和点卷积来实现,有效的减少了模型运算过程参数数目,下面进行常规卷积和DW卷积之间的参数运算量对比,假设二者输入均为RGB图像,输出channel=4。
下图为常规卷积,参数计算量为:3×3×3×4=108。
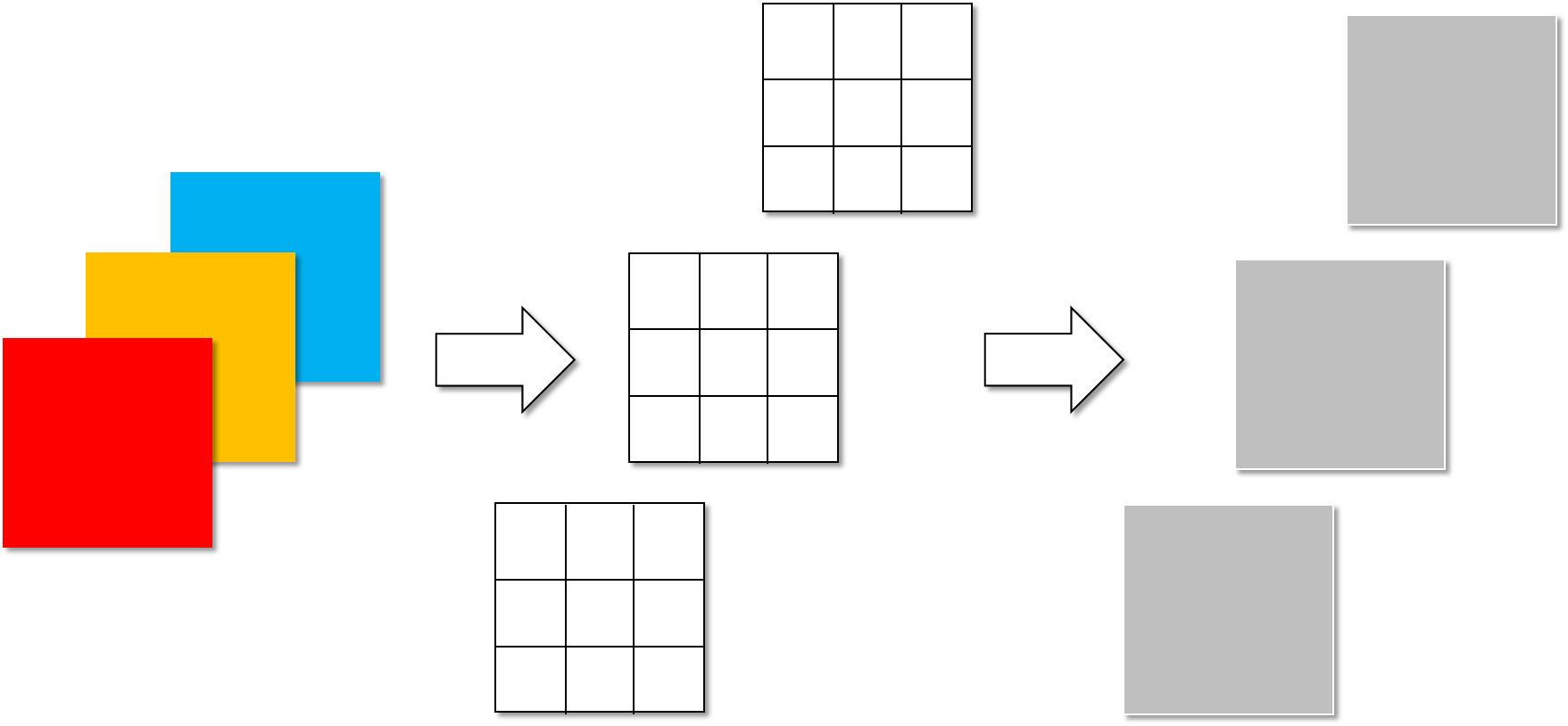
DW卷积分为两步进行,首先是下图所示的Depthwise convolution,也就是对每一层输入进行卷积,输出channel=输入的channel,下图为深度卷积,参数计算量为:3×3×3=27。
第二部分是下图所示的Pointwise convolution,参数计算量为1×1×3×4=12。
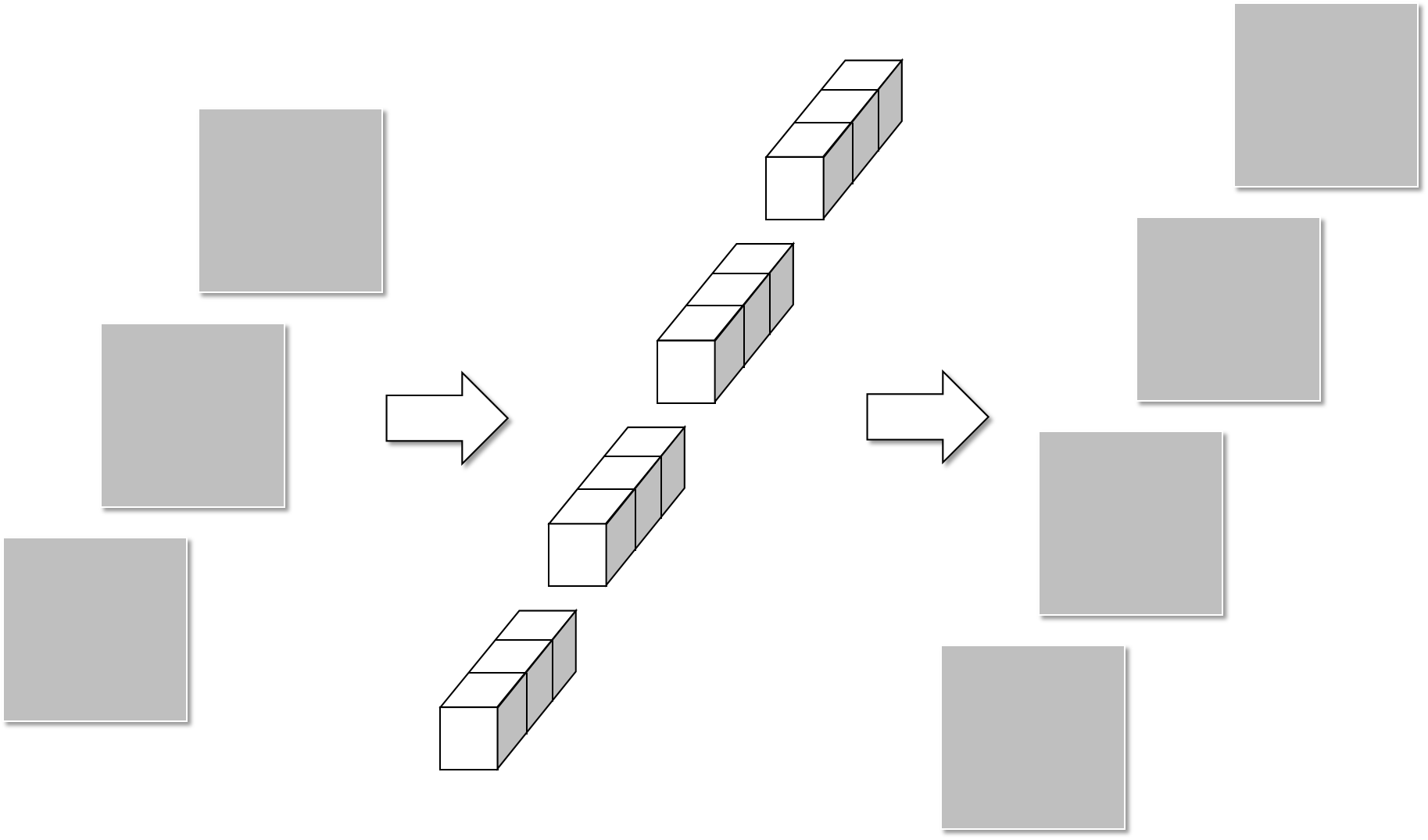
最终两部分参数计算量合起来为39,远小于常规卷积的108。
1.2 超参数:
主要目的是为了实现更小、计算代价更少的模型。
1.2.1 :宽度乘数:
这里为了显示方便,我将对应变量含义都标注到了常规卷积的图片上。 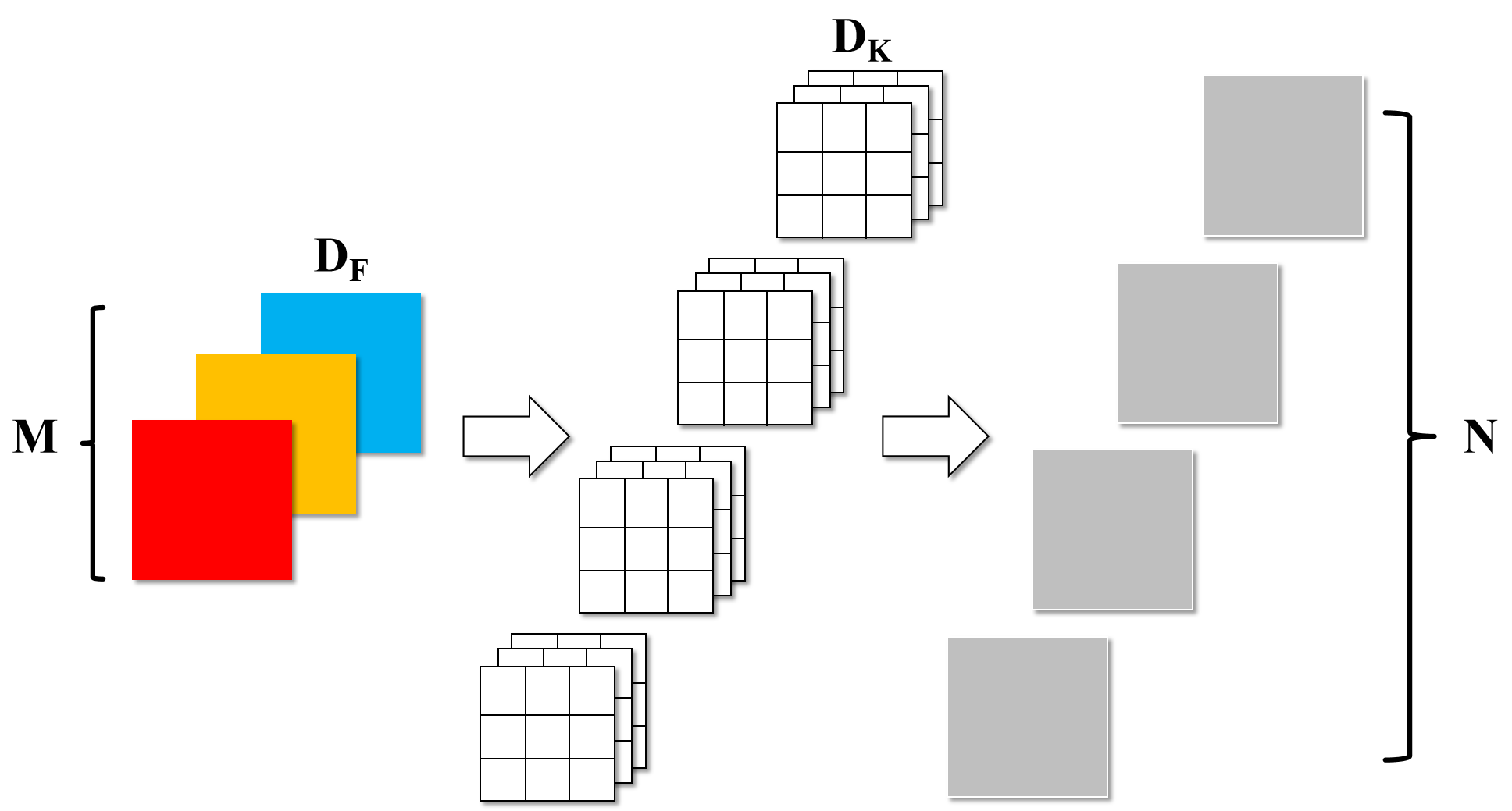
就能推算出DW卷积的参数计算公式为:$ D_k\cdot D_k\cdot M\cdot D_F\cdot D_F+M\cdot N\cdot D_F\cdot D_F$,其中$D_k、D_F$分别为卷积核尺寸和输入图像尺寸。
而宽度乘数$\alpha$(width multiplier),取值范围为(0,1],主要作用就是来控制feature map的channel数,将输入channel为$ \alpha M$,输出channel变为$ \alpha N$。
因此加入后,DW卷积的参数计算公式就变为:$ D_k\cdot D_k\cdot \alpha M\cdot D_F\cdot D_F+\alpha M\cdot \alpha N\cdot D_F\cdot D_F$,原论文中的对比试验效果如下图所示,网络结构前面的小数就是宽度乘子。
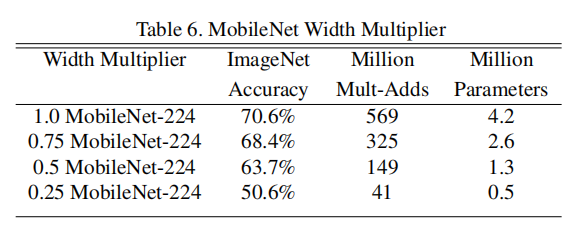
1.2.2 分辨率乘数:
分辨率乘数$\rho$(resolution multiplier),取值范围也是(0,1],通过改变输入图像的尺寸,来减少神经网络的计算代价,因此输入尺寸由$ \beta D_F$。
加入后, DW卷积的参数计算公式变为:$ D_k\cdot D_k\cdot \alpha M\cdot \beta D_F\cdot \beta D_F+M\cdot \alpha N\cdot \beta D_F\cdot \beta D_F$,原论文中的对比试验效果如下图所示,网络结构后面不同的数字就是变化后的输入尺寸。
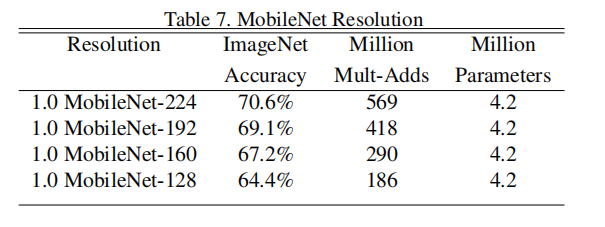
2. MobileNet V2:
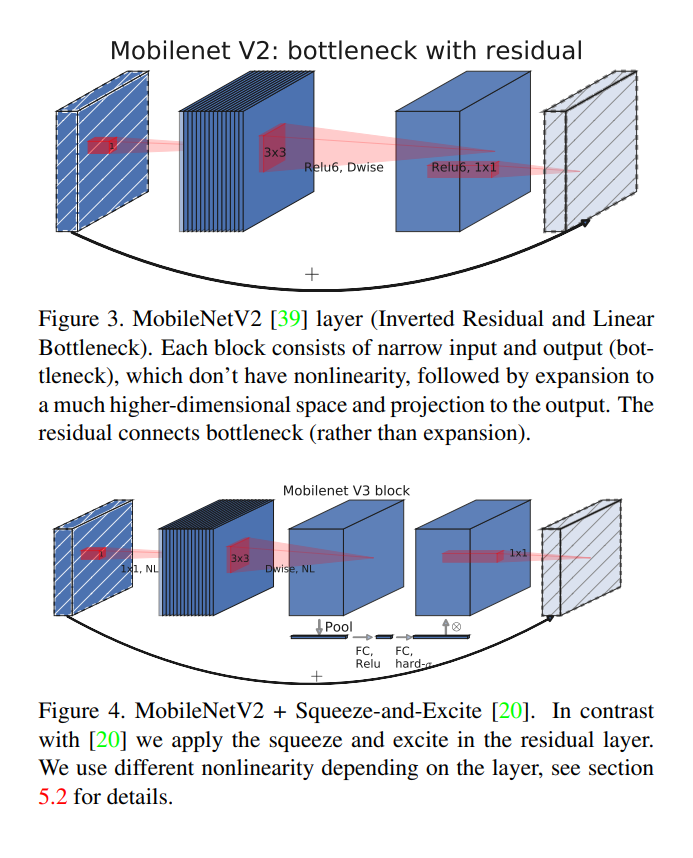
在2018年由Google团队提出,相比于V1,主要是使用了有线性瓶颈的逆残差结构,其整体网络结构如下所示:

2.1 有线性瓶颈的逆残差结构:
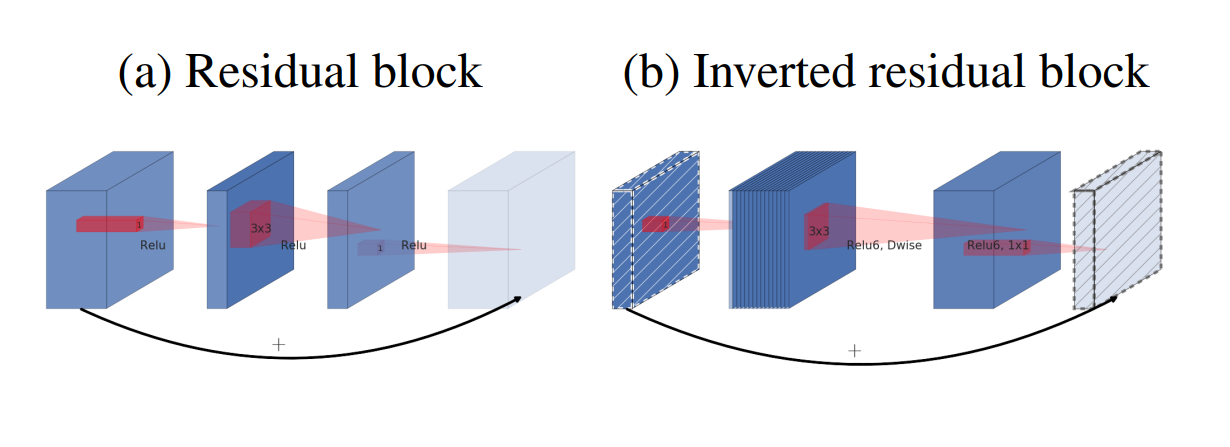
上图所示为残差模块和逆残差模块之间的对比,二者每一层的对比如下表。如果大家熟悉残差模块的话,会发现BottleNeck结构很相似,然后再把里面3×3的常规卷积替换为了深度可分卷积。
至于逆残差结构中,通过模块中的第一个卷积操作,可以发现feature map深度增加了,也就是实现了升维,而这是通过上面网络结构表中的 膨胀系数$t$ 实现的,膨胀后的通道数变为$ channel_in \times t$。
| Residual block | Inverted residual block |
|---|---|
| 1×1卷积降维 | 1×1卷积升维 |
| 3×3卷积 | 3×3卷积 |
| 1×1卷积升维 | 1×1卷积降维 |
逆残差结构还引入了ReLU6,其公式为:$ReLU(x) = min(max(0,x),6)$。其与ReLU之间的对比,直观展示如下:
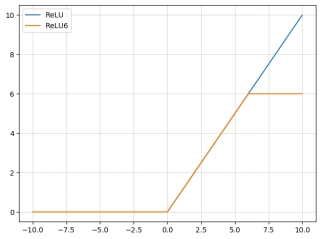
此外,有线性瓶颈的逆残差结构的最后一层的激活函数替换为了线性激活函数。(这里原文是给了一个实验对比,但我理解不是很透彻,先不详细展开了,等我之后再去瞅瞅),V3的代码里是用了线性映射。
3. MobileNet V3:
MobileNet V3在2019年由Google团队提出,它保留了前两代的DW卷积、超参数α、β以及有线性瓶颈的逆残差结构,加入基于压缩-激励结构(squeeze - excitation structure)的轻量级注意力机制更新了block,并对较为耗时的Last Stage重新进行了设计,其中Small版的网络结构如下图所示:
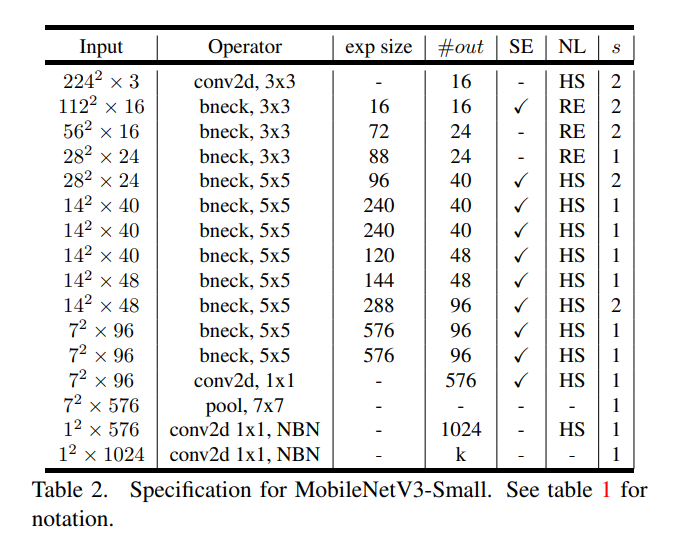
3.1 Bneck:
更改后的block结构和V2 中的对比如下图所示:
插一句:注意力机制借鉴了我们通过眼睛在观察事物的时候,往往会聚焦在某些物体上,从而过滤掉一些无用的信息,因此注意力机制的作用就是通过调整每个通道的权重不同,从而实现对输入数据的每个部位的关注度不同,从而提高模型对关键特征的识别能力,我不太确定这个注意力是不是起源于Transformer,其应用位置如下图所示:
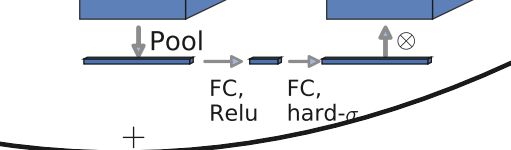
该结构的简化举例为(这里又双叒叕借用了大佬的图,之后再贴链接)
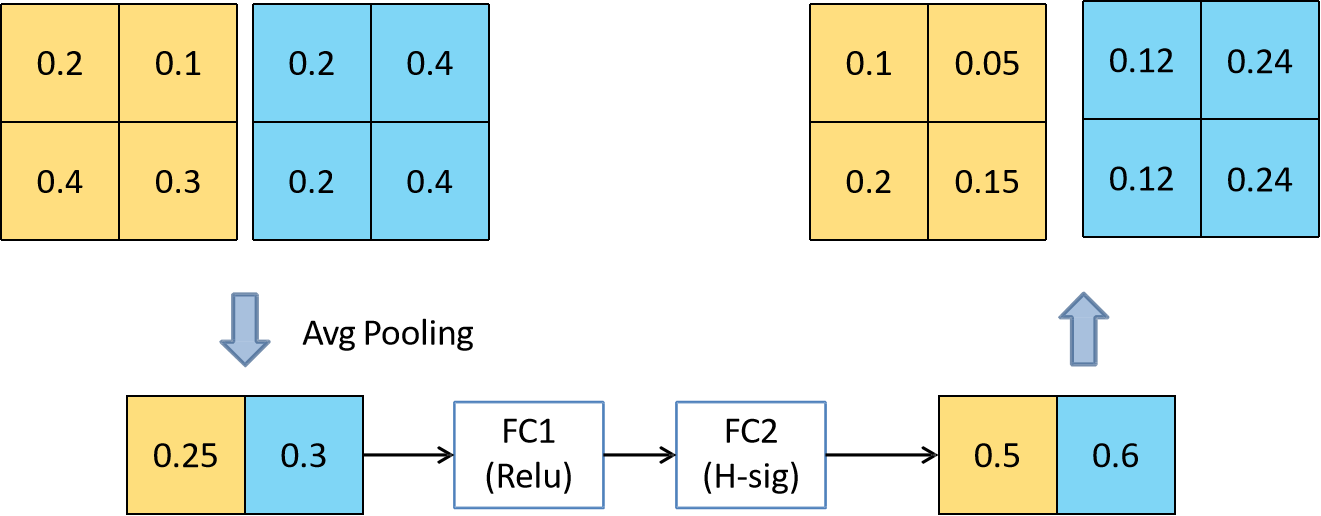
其中用到的新的激活函数hard-sigmoid,公式为:$ hard-sigmoid(x)=\frac{ReLU6(X+3)}{6}$
3.2 Last Stage:
简化前后对比,清楚看到其中减少了层结构,最终的效果能够减少模型运行的时间为7ms大约占据一次运行时间的11%:
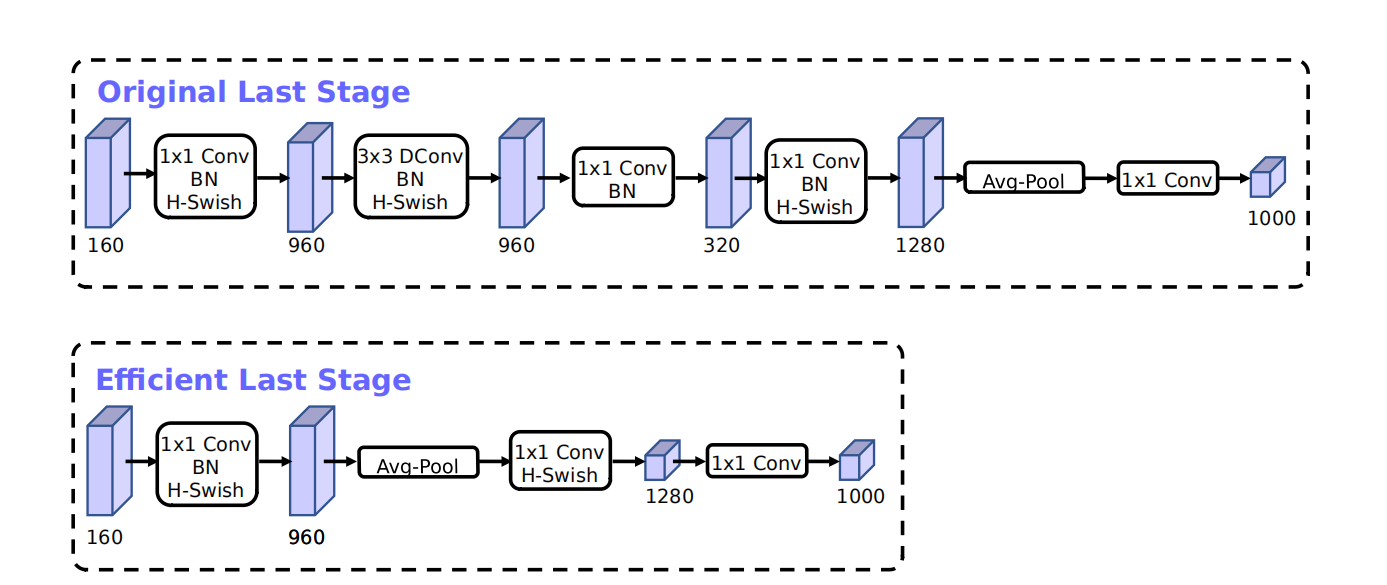
其中用到的新的激活函数hard-swish,公式为:$ hard-swish=\frac{x \cdot ReLU6(x+3)}{6} $
文档信息
- 本文作者:Guoziyu
- 本文链接:https://mateguo1.github.io/2021/05/28/MobileNet/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)