Swin Transformer:
继续,这篇来整理下Swin Transformer的相关知识。论文链接:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,再顺便给出一篇文章,用动图详细地解释了其中的原理,很值得一看,A Comprehensive Guide to Microsoft’s Swin Transformer。
将Transformer从语言处理领域运用到视觉领域的两个挑战: (1) 相较于文本中固定尺寸的词向量,图像的尺寸则会有较多的、较大的变化; (2) 相较于文本,图像的分辨率较高(数据量),尤其像是在语义分割这种需要处理像素数据级别数据的任务中。
之前的ViT有一些弊端,像是需要较大的训练集来实现较好的效果,以及它的结构不是很适合用作密集预测任务的基础网络(或者是处理的图像分辨率较高,因为运算量会按照图像尺寸的次方级增加)。
1. Architecture:
下图是原文给出的Swin-T的整体结构,接下来就按照顺序详细展开。
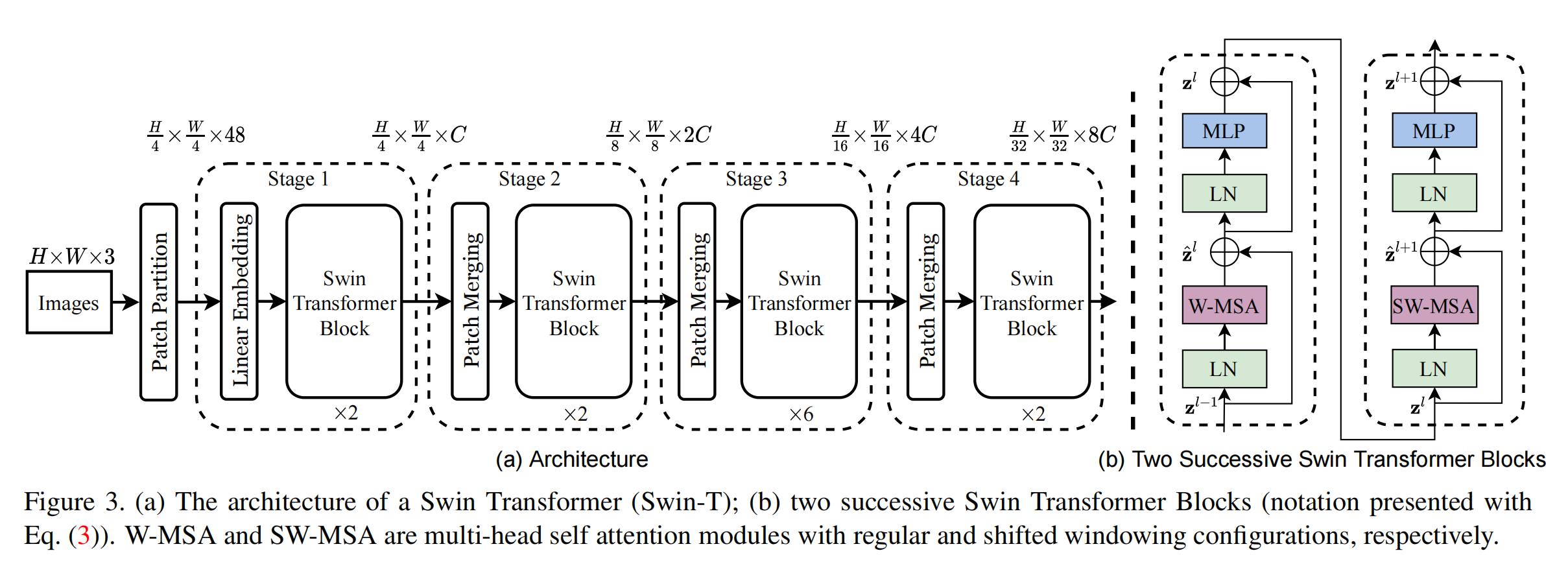
1.1 Patch Spliting Module:
首先经过这个模块,该模块和ViT的功能相同,每一个patch都被当作token来对待,论文中提到使用的patch size为4,因此每一个patch形状就是$4\times 4\times3$。

1.2 Linear Embedding Layer:
再经过这一层,将映射层任意维度,这个维度被定义为C,是一个可以更改的参数。
1.3 Swin Transformer blocks:
然后再进入这个模块,其结构如下图所示,然后具体的顺序可以结合下图和公式来理解,也不算很复杂,相比于之前ViT中的内容,比较陌生的是W-MSA,下面会详细整理下,其他内容就不再详细展开了,可以参考我之前的博文Vision Transformer。
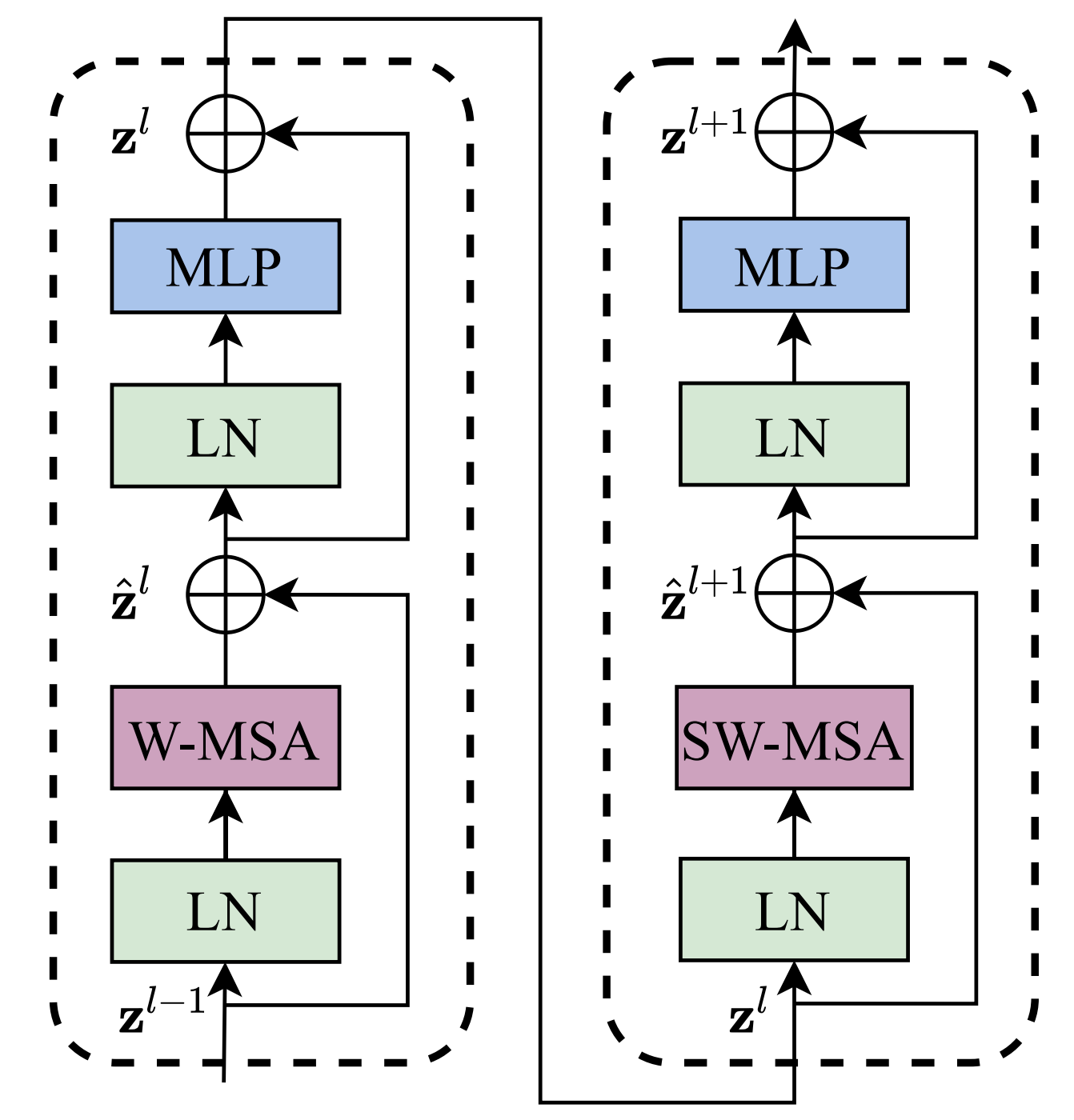
1.3.1 (S)W-MSA:
(S)W-MSA全称应为(Shifted) Window Multi-Head Self-Attention,多头注意力机制可以参考之前的博文Transformer,这里就在之前的基础上,一步步展开。

首先来看静态的W-MSA,为了有效的建模,作者提出W-MSA,也就是在不重合的窗口中计算自注意力,每一个窗口含有$M\times M$(默认值为7)个patch,然后用公式对比下MSA(这里的计算,在Transformer有详细讲解,或者可以参考这篇文章内容,深度学习之NLP学习笔记(七)— Transformer复杂度分析),二者的计算量(这里忽略了Softmax的复杂度):
\[\begin{align} &\Omega(MSA)=4hwC^2+2(hw)^2C \\ &\Omega(W-MSA)=4hwC^2+2M^2hwC \end{align}\]
而动态的(严格来讲也不算动态,这样说比较方便理解)SW-MSA,则是将窗口向着右下角移动,因此就会产生尺寸小于$M\times M$的patch,因此就要将这些patch移动去填补空缺。

1.4 Relative Position Bias:
在计算自注意力的时候,加入了相对位置偏移,从而能够有效提升模型的效果。公式如下:
\[Attention(Q,K,V)=SoftMax(\frac{QK^T}{\sqrt{d}}+B)V\]然后文章针对上述结构进行了大量的消融实验,这些等之后再补充。
文档信息
- 本文作者:Guoziyu
- 本文链接:https://mateguo1.github.io/2021/11/30/Swin_Transformer/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)